
作者:翻翻,编辑:odette,题图来自:AI生成
还记得之前OpenAI的高层大地震吗?
引发了Sam Altman被罢免、联合创始人Greg Brockman离职、OpenAI内部矛盾不断激化的,是一个名叫Q*(读作Q-Star)的项目。
据知情人士透露,当时Q*项目取得了重大进展,已经可以解决基本的数学问题。与只能解决有限数量运算的计算器不同,与每次都给同一道题不同答案的GPT-4不同,Q*可能已经有了概括、学习和理解的能力,而这正是迈向AGI关键的一步。OpenAI的研究人员向董事会致信警告,Q*的重大发现可能威胁全人类,而Sam Altman隐瞒了这一点。
OpenAI内部翻天覆地,而OpenAI本身从未正面回应过Q*的存在。
今天,OpenAI突然发布了一个新模型,这个模型目前还是前瞻版,它就是传说中的Q*,后来的代号“Strawberry”,如今的OpenAI o1-preview。

解决复杂问题的新推理模型,和ChatGPT不是一个系列了|OpenAI
o,还是“omini”,包罗万象的o,只不过据OpenAI表示,这次的模型“代表了人工智能的新高度”,和之前的大模型在工作方式上大有区别,因此可以单独成立一个新系列,从1开始重新算起(GPT5:我老了!)。
至于这个模型是不是像Ilya Sutskever和其他反水的OpenAI前核心科学家判断的那样会“威胁人类”、在道德约束不完善的情况下把人类推进AGI(通用人工智能)时代,大家可以看完文章再自己判断。
o1,跑赢一切
首先是耳熟能详的跑分环节。
每一代大模型横空出世,都会跑出空前绝后的新高度,但这次的o1有本质的不同。
目前比较流行的大模型大多都以聊天机器人的形式出现,思考路径难以解释,而且发展方向是多模态(能说能看能听),在语气和反应方面越来越像人。o1和它们不一样。
首先它的目标不是越来越快,甚至是越来越慢。
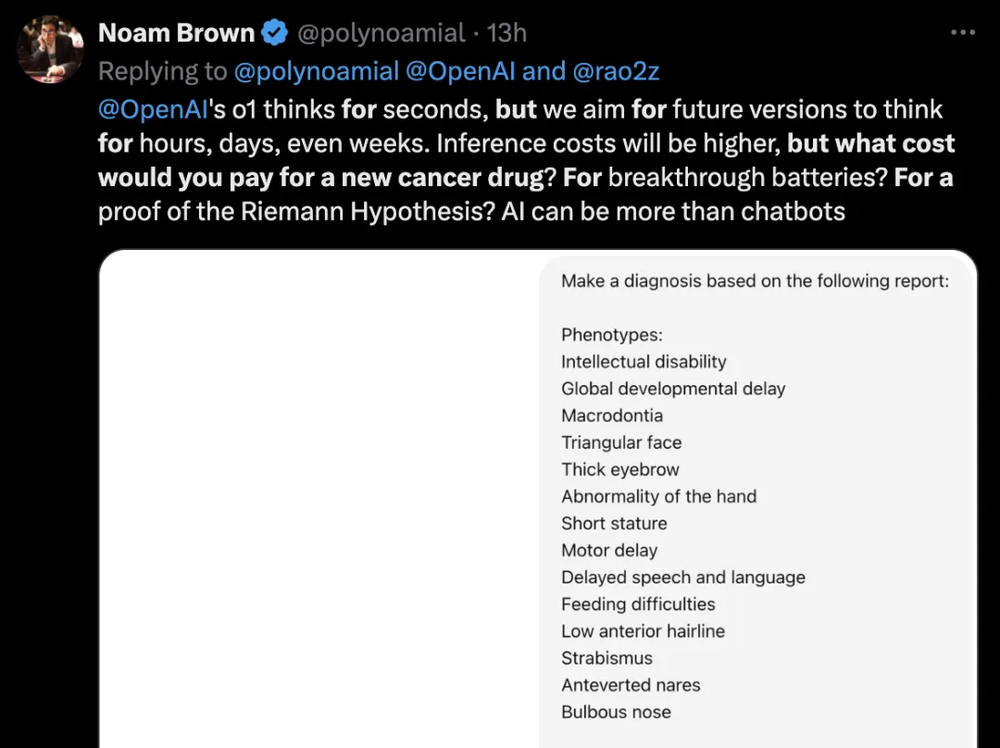
OpenAI科学家Noam Brown称,目前o1几秒就能给出答案,但未来它要能进行几小时、几天,甚至几周的思考。之后附上了一张图,o1在十几秒的思考后给一个病例做出了诊断。Noam Brown的言下之意,推理时间长,意味着模型能构建更长的思维链,进行更深入的思考。
其次,o1突破了之前大语言模型的死穴,数学。
AIME,美国数学邀请赛,比奥赛简单点,比SAT难很多,一般用来选拔全美国数学最优秀的高中生。让GPT4-o来写邀请赛的题,只得了12分,但o1一次性答题得了74分。如果采样1000次,再对1000个样本进行评分函数重新排序的话(这样更能反映模型的期望水平),o1得了93分,可以跻身全美前500 名,可以入围美国数学奥赛了。
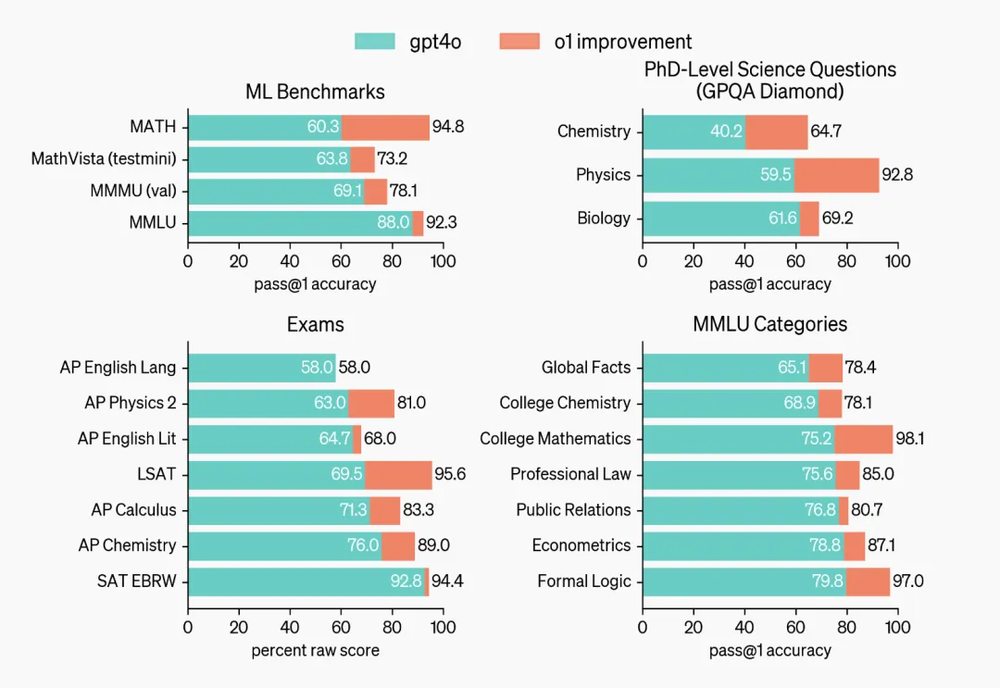
o1和GPT-4o表现对比,数学上的进步非常大|OpenAI
让o1去写2024年国际信息学奥林匹克竞赛(IOI)的题,它在10小时内,每题最多允许提交50次的情况下,取得了213分,在人类选手里排前49%。如果把提交次数放开到10000次,o1能得362.14分,可以拿到IOI金牌保送清华。
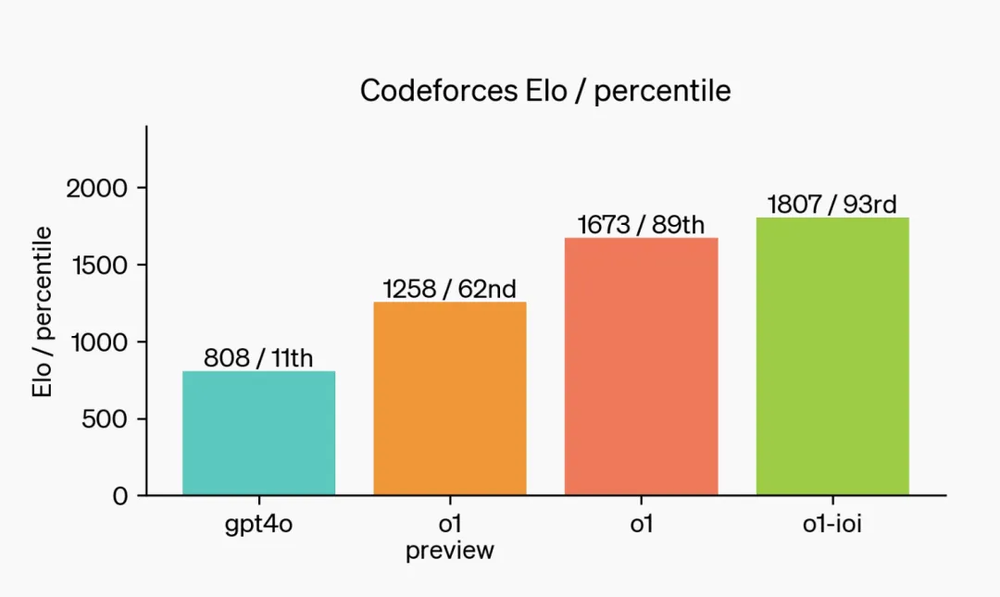
在实际测试中,使用的是o1的微调版本,不是我们能用的前瞻版本|OpenAI
另外还有好多有的没的测试。比如在GPQA(一个综合了理化生的智力测试)里,o1在某些问题上超过了相关领域的博士。
简而言之,在已经很强的领域内卷早就不是o1的目的,在大语言模型不擅长的复杂逻辑上实现突破才是。
退一步,进两步
就像上面说的,o1的反应速度变慢了。
它会花更多时间思考,然后再做出反应,然后不断完善思维过程,尝试不同策略,并从错误中学习。这一点很可怕。
而且o1现在不是个多模态的模型,OpenAI用了两年让大模型能看能听,今朝返璞归真了,o1只能接受字符输入。
变慢和变单调,对o1来说,是退一步进两步。已经用上o1的人表示o1是他们用过的最聪明的模型,和它的对话已经超越了之前的小打小闹范畴。
在一个测试里,用户问了o1一个逻辑悖论问题:“这个问题的答案里有几个字?”
o1想了十秒钟,并且展示了思考过程。首先它想到,这是一个自指悖论,或者是递归问题,没有确定答案的时候就无法确定答案的字数,“避免不必要的表述对回答的清晰简洁很重要”。下一步是计算字数,需要让句子中出现的数字和句子的字数相匹配。然后它列举了很多句子,在里面找出最合适的匹配选项,它发现“这有五个字”有五个字,于是把句子结构换成完整的答复后,五应该换成七。
于是它回答:“答案里有七个字。”
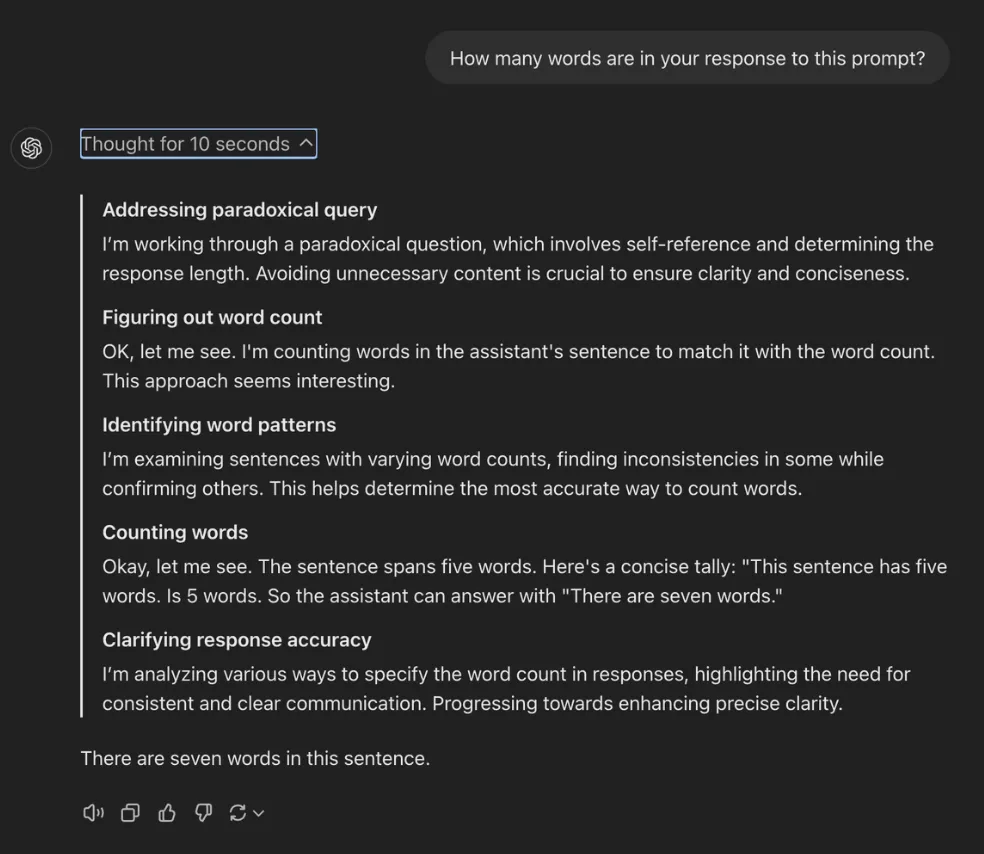
这个推理过程已经和我的推理过程区别不大了|X
在另一个例子里,o1回答“straberry里有几个r”这个简单的问题,用了5.6秒,631个token。
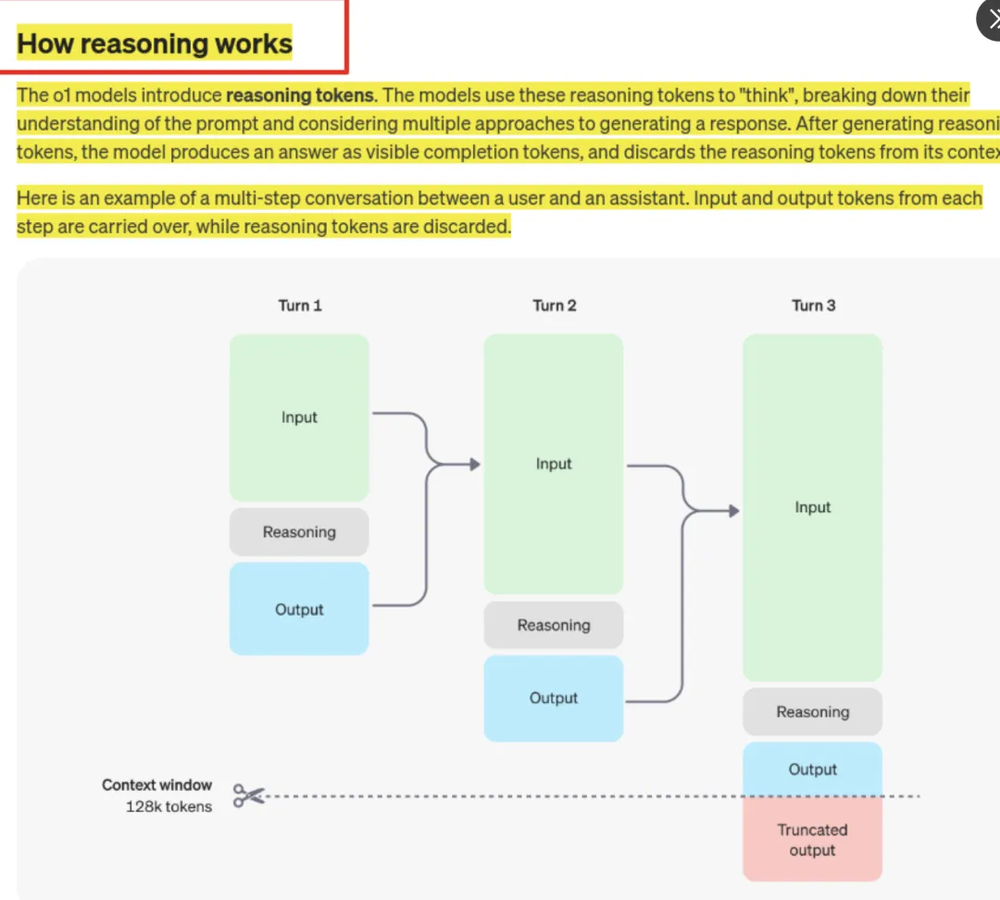
从上面的例子,可以看出o1的工作方式已经和ChatGPT有了本质区别。现在的o1加入了推理token,会把一个问题拆分成多个步骤,再分别思考,之后再除去推理token生成答案。
下图展示了思路链的工作方式,这也解释了为什么o1的响应速度变慢了。
在用o1的时候,不妨用一些经典的逻辑问题和数学问题来检验它的能力
也许在回答简单问题的时候,是否进行多轮推理的区别并不明显,但如果是用来解决写代码、做数学题,和科学领域的复杂问题,这种思考能力就是必不可少的了。
OpenAI在论文中说,现在,医疗人员可以用o1来标注细胞测序数据,物理学家可以用o1生成量子光学所需的复杂数学公式,各领域的开发人员可以使用o1来构建和执行多步骤工作流程。
更重要的是,这是一种思维模式的雏形,是智慧的早期形态。
新的模型,新的习惯
由于o1的工作方式已经和ChatGPT不一样了,之前看到的那些教你写prompts的教程也不再适用——现在的情况下,过多的描述只会消耗海量的token,而不一定会获得更好的结果。
为了让所有用户都明白这一点,OpenAI写了新的token指南。在指南中,OpenAI说明,在o1里最好的prompts是直接而简洁的,指挥模型一步一步做或者给若干分散的提示词可能会适得其反。以下是几个官方建议:
Prompts要简单直接。模型对简短清晰的指令响应效果最好,不需要过多的指导。
在prompts中避免思维链。o1会自己进行内部推理,因此引导它一步一步思考和解释你的思考路径都是没用的。
最好使用分隔符来提高清晰度。用“”、<>、§等分隔符,清晰地区分prompts的不同部分,以帮助模型分批处理问题。
限制检索增强生成中的额外上下文。只提供最相关的信息,避免模型过度思考。

看到第三条的时候,我对这个格式产生了一丝熟悉的感觉。未来的程序员很有可能要用自然语言编程,基本的指令还是那些,只不过变成了大白话。按照最新的指南,一个好的prompts看起来会是这样的:
或者这样的:
§主持人§作家§酒吧老板§油画家§皮匠§银匠§歌手§手鼓艺人§背包客§黄金左脸§法国骑士§禅宗弟子§
其他的就交给模型自己想去吧。
给我一分钟,做出3D贪吃蛇
用贪吃蛇举例子是有原因的。o1发布不到一天,就有人用它做了很多尝试,其中就包括3D贪吃蛇。
X上的@Ammaar Reshi用了极其简单的prompts,仅用一分钟的时间就写出了一个3D贪吃蛇,而且o1还手把手教他怎么用代码。
学会写prompts了吗?|@Ammaar Reshi
效果虽然有点简陋,但谁都不能说它不是贪吃蛇。
而且还挺好玩的|@Ammaar Reshi
网友@James Wade用o1做了个数据分析app,能显示每个分布的简短描述和示例,只用了15分钟,这还包括了部署的时间。他说:之前从来没有想过做这样的东西,之前太麻烦了。
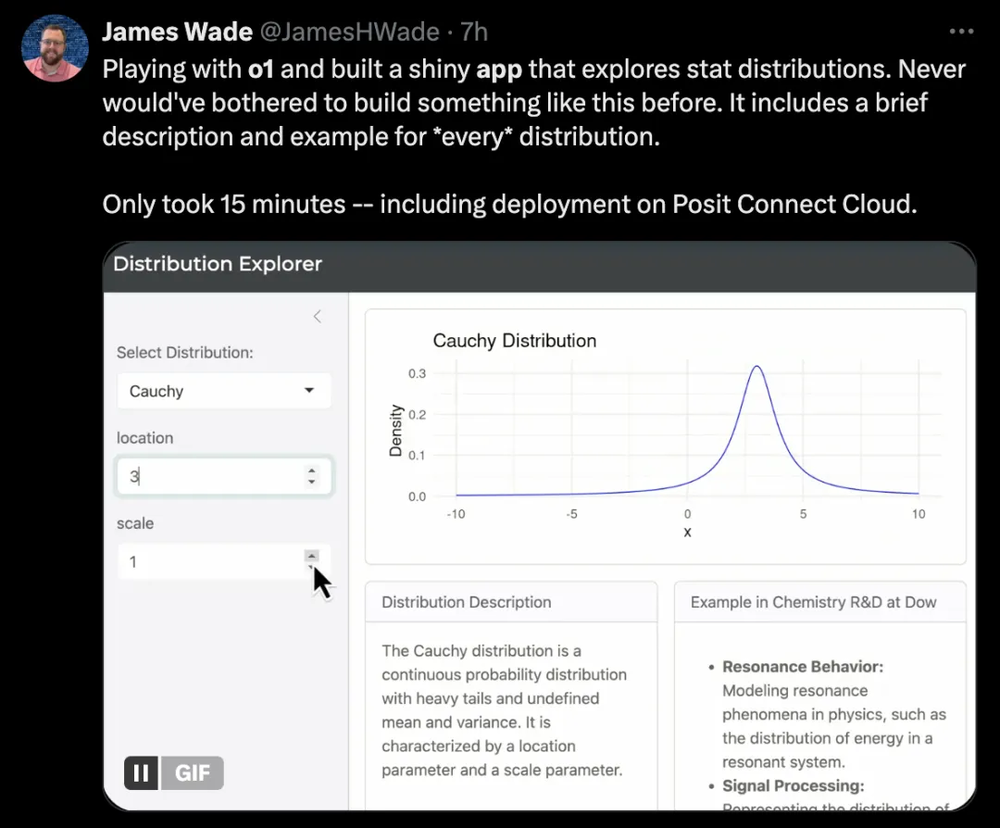
效果如图|@James Wade
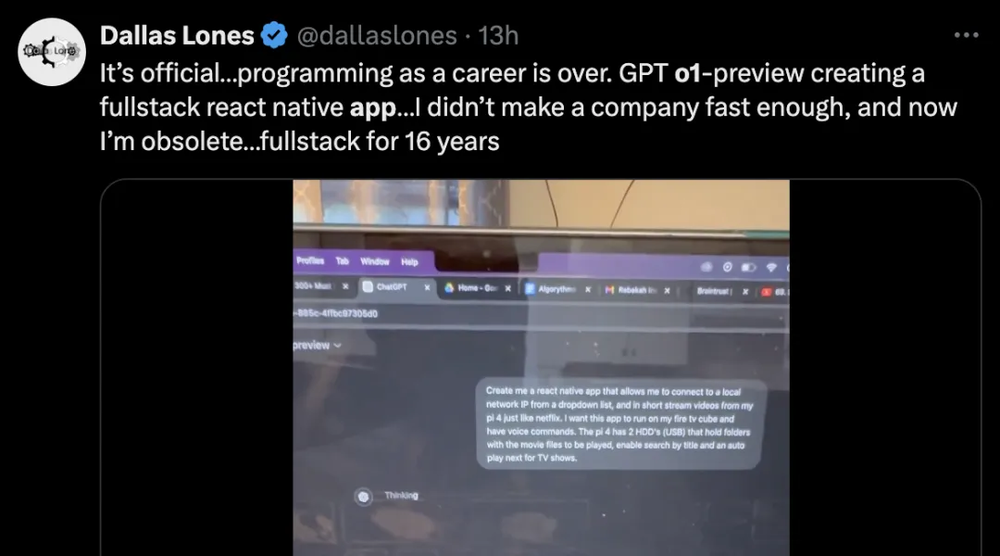
另一位工作了16年的全栈工程师@Dallas Lones,用几分钟做了一个React Native全栈开发App之后感慨道,自己当初没有尽快创业,如今这门手艺已经成了时代的眼泪。他说,“编程作为一个职业,在今天正式终结了”。
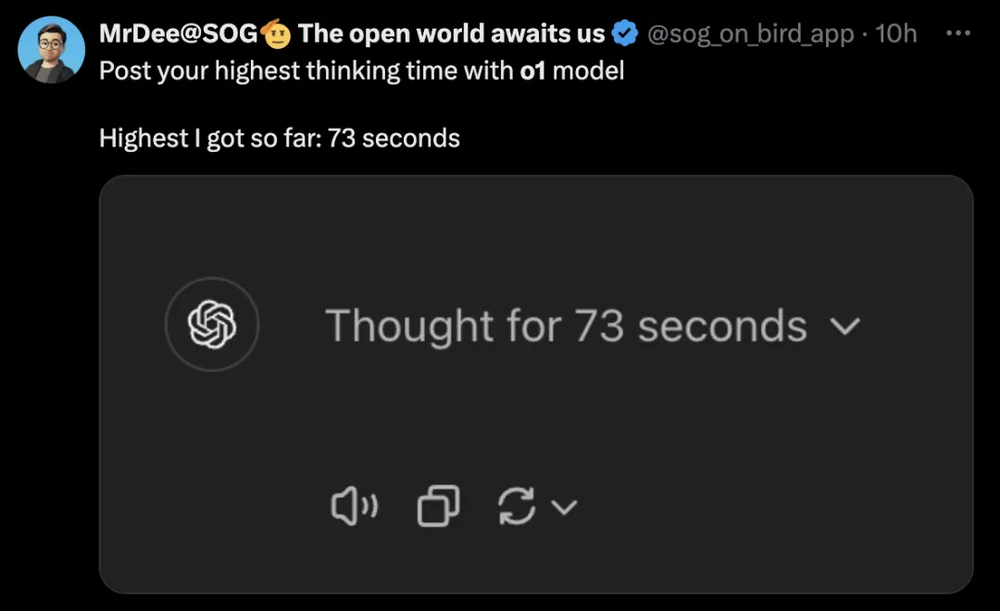
还有更多的人在挑战o1的极限,已经有人玩起了“看谁的问题更刁钻能让o1思考的时间最长”的游戏。
目前,o1先对ChatGPT Plus和Team用户开放,而API访问权限将首先开放给在OpenAI API上花费超过1000美元的5级用户。下一步,OpenAI将逐步向免费用户开放低配版的o1-mini。
这会是人类的夕阳吗?